
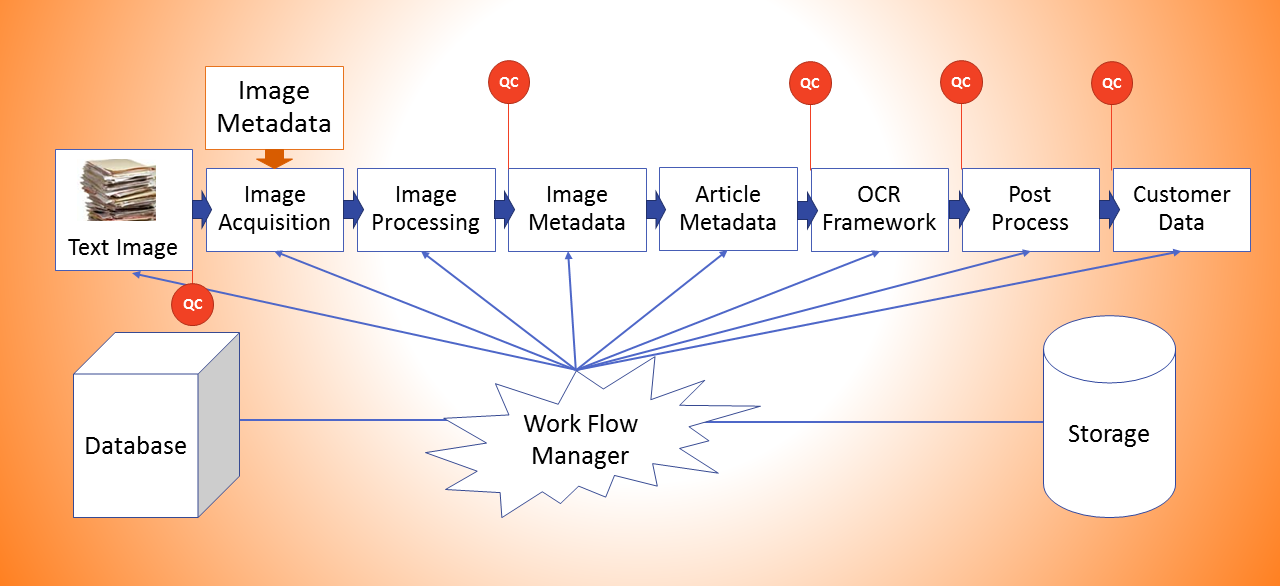
Newspaper Digitisation
In order to make a newspaper available for searching on the Internet, the following digitisation processes must take place:
- the microfilm copy or paper original is scanned
- master and Web image files are generated
- metadata is assigned for each issue, page, and article to improve the search results of the newspaper
- OCR software is run over high resolution images to create searchable full text
- OCR text, images, and metadata are imported into a digital library software program
Methodology
Microfilm Scanning
The best microfilm for image projects is an unused, negative, first generation copy of the master. Microfilm rolls are scanned in batches. Each 35mm roll contains approximately 700 frames/images (sometimes a frame is a double page), which are scanned at 300-400 dpi, dependent upon image quality. The master image is a cropped, de-skewed; 8-bit greyscale or bi-tonal TIFF master scan, averaging 34 MB.
Image processing is always a trade-off. When an algorithm is applied to enhance an aspect of the image or eliminate a defect in a page (for example, bleed-through), the algorithm may at the same time adversely affect some other aspect of the image. Quality control steps are built in at critical points; however, the final quality control occurs when the customer reviews the delivered images.
Image Formats & Resolutions
A number of decisions needed to be made about the master and Web images including file format (TIFF, JPEG, JPEG2000, or PDF Searchable Image), bit depth (greyscale or bi-tonal), and resolution (200dpi, 300dpi, 400dpi).
Metadata
The archival technician assigns both page level and article level metadata. Each page image is tagged with the following metadata:
- publication title
- publication date
- volume and issue number
- page number
The page image is then segmented into articles and the following article level metadata is keyed:
- headline
- byline
- classification
- whether the article is a lead story
Metadata are important because, when combined with the full text, they can improve search accuracy and enable searches to be constrained to particular sections of the paper. For example, classifications enable end users to search the editorials, news articles, cartoons, or advertisements, and/or to search for a particular by-line.
OCR Processing
OCR creates searchable text from digital images. Many factors affect the accuracy of OCR. These range from the quality of the source image to the complexity of layouts (many commercial OCR products do not deal well with the complex formats found in newspapers).
Smaller fonts, often used in older newspapers, require higher image resolution for optimal OCR performance. Digitising historic newspapers is a much more complex task than generating text from other documents and states; nothing but the most robust OCR software should be used for historic newspapers. OCR is run on article images, or more precisely, on a number of rectangular regions that comprise an article. The resulting OCR text is assembled for each article as well as for the entire page.
XML Conversion
Conversion of textual content into XML / SGML format as per the DTD (Document Type Definition) provided by the client. The text from the source documents is first converted into ASCII format by using OCR technique, (as described above) followed by analysis of the text contents, incorporation of XML / SGML tags and parser validation of tagged data with the help of our own custom built application software.
Digital Object Production
The final step in production is the assembly of digital objects comprising the images, OCR text, and metadata. Two deliverable’s are sent to clients on DVD:
Objects for each issue of the newspaper consisting of PDF Searchable Image files containing 125 dpi JPEG images and OCR text, JPEG thumbnails, and XML files describing the location of each word discovered on the page and the metadata gathered during processing. Archival 4-bit greyscale TIFF images.
Quality Control
Manual and automated quality control steps are built into the scanning process. For example, a missing page report is generated if the numerical sequence indicates a page is missing. By using above methodology 99.995% accuracy is possible.